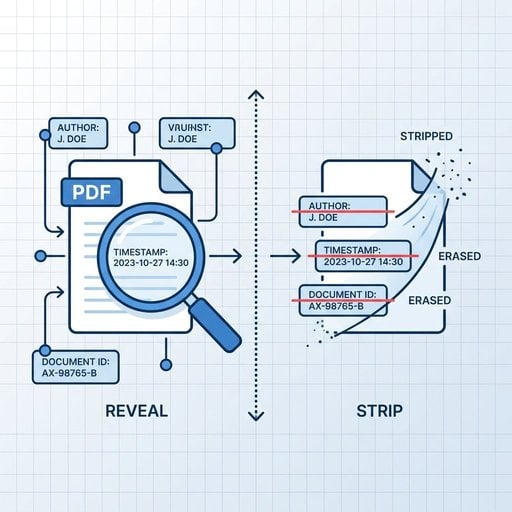
PDFのメタデータ削除とは、PDFファイルに埋め込まれた隠し情報を取り除くプロセスです。具体的には、作成者の氏名、使用したソフトウェア名、編集履歴、場合によってはGPS座標なども含まれます。多くの人は、こうしたデータがファイルに付随したまま共有されていることに気づいていません。契約書を送る弁護士、情報源を守るジャーナリスト、あるいはプライバシーを重視する一般ユーザーにとっても、PDFの隠しデータを削除するスキルは実用的で価値があります。
PDFメタデータとは?
PDFファイルは、画面に表示されるページだけで構成されているわけではありません。Adobeの PDF仕様 では、メタデータが格納される場所として2つの独立した領域が定義されています。
- Document Information Dictionary - PDF 1.0から存在するレガシーなキーバリュー形式のストアです。Author、Title、Subject、Keywords、Creator、Producer、CreationDate、ModDateといったフィールドを保持します。
- XMP (Extensible Metadata Platform) - Adobeが導入したXMLベースのより新しい形式で、サードパーティ製ソフトウェアが定義したカスタムプロパティを含む、より詳細な情報を格納できます。
この2つは同一ファイル内に同時に存在でき、内容が一致しないこともあります。ツールによっては一方しかクリアしないものもあり、表面的なクリーンアップだけでは機密データが残ってしまう可能性があります。
実際に露出する隠しデータの内容
PDFの作成方法によって異なりますが、ファイル内に潜んでいる可能性のある情報を整理すると次のようになります。
| メタデータフィールド | 露出する内容 | 格納場所 |
|---|---|---|
| Author | ソフトウェアに登録された名前 - 個人のフルネームや企業のユーザー名が含まれることが多い | Info Dictionary + XMP |
| Creator / Producer | ファイルを作成したアプリケーション名(例: "Microsoft Word 2019"、"Adobe Acrobat Pro DC 2023") | Info Dictionary + XMP |
| Creation Date / Mod Date | タイムゾーンを含む正確なタイムスタンプ。文書に記載された日付と矛盾する場合がある | Info Dictionary + XMP |
| Revision History | 文書が保存・編集された回数 | XMP (xmpMM namespace) |
| Document ID | 同一文書の複数バージョンを紐付けられる一意の識別子 | XMP |
| カスタムプロパティ | 会社名、部署名、法的ステータス、内部タグなど - Word、SharePoint、法律系ソフトウェアが付加するもの | Info Dictionary + XMP |
| 埋め込みフォント / リソース | 内部ブランディングや独自ソフトウェアの手がかりとなるフォント名 | PDFリソースディクショナリ |
PDFの隠しデータがもたらす現実のリスク
これは単なる理論上の問題ではありません。PDFの隠しデータが深刻な被害をもたらした事例が実際に記録されています。
- トニー・ブレアのイラク文書流出事件(2003年) - イラク戦争を正当化するために英国政府が公開したPDFに、変更履歴と作成者名がそのまま埋め込まれていました。ジャーナリストがその情報から文書を起草した官僚の名前を特定し、大きな政治的スキャンダルに発展しました。
- 法的書類の提出ミス - 弁護士事務所が、相手方弁護士のコメント、変更履歴、内部メモが埋め込まれたままのPDFを誤って提出してしまった事例があります。
- ジャーナリズムの現場 - 文書をリークした情報源が、PDFのAuthorフィールドやDocument IDからログイン情報を辿られて特定されるリスクがあります。
- 入札・調達プロセス - 企業が入札書類を提出する前に、会計ソフトウェアが付加したカスタムメタデータフィールドを通じて、内部のコスト構造が競合他社に漏れてしまった事例もあります。
PDFメタデータを削除する方法
PDFのメタデータを削除する方法はいくつかあり、それぞれにトレードオフがあります。
方法1: Adobe Acrobat Pro(Windows / Mac)
Acrobat Proをすでに利用している方には、最も徹底したデスクトップ向けの方法です。
- Acrobat ProでPDFを開きます。
- ツール > 墨消し > ドキュメントのサニタイズ に進みます。これにより、メタデータ、埋め込みコンテンツ、スクリプト、隠しレイヤーが一括で削除されます。
- または、 ファイル > プロパティ > 説明 から各フィールドを手動でクリアすることもできますが、この方法ではInfo Dictionaryのみが対象となり、XMPには対応していません。
方法2: ExifTool(無料 / コマンドライン)
Phil Harvey氏が開発したExifTool は、PDFを含む数十種類のファイル形式のメタデータ操作において標準的なツールです。無料で利用でき、Windows、Mac、Linuxに対応しています。
PDFからすべてのメタデータを削除するには:
exiftool -all= yourfile.pdf元のファイルを保持しながらクリーンなコピーを保存するには:
exiftool -all= -o cleanfile.pdf yourfile.pdfExifToolはInfo DictionaryとXMPパケットの両方を削除します。ただし、埋め込みフォント、隠しレイヤー、コメントは削除されません。それらを取り除くには、AcrobatのサニタイズFunctionまたは専用のPDFサニタイザーが必要です。
方法3: PDFとして印刷(手軽な方法)
PDFを開き、OSに組み込まれたPDFプリンター(WindowsのPDFとして印刷、macOSのPDFとして保存)を使って新しいPDFとして出力する方法です。ドキュメントが実質的に再レンダリングされるため、ほとんどのメタデータが除去されます。ただし、インタラクティブな要素がフラット化され、ブックマークが失われたり、品質が低下したりする場合があります。シンプルなテキスト文書には適していますが、複雑なフォームやレイヤー構造を持つグラフィックには向きません。
方法4: Pythonとpikepdf(開発者向け)
プログラムでPDFを処理する場合、 pikepdf はQPDFをベースにしたクリーンなPythonライブラリで、メタデータを精密にコントロールできます。
import pikepdf
with pikepdf.open("input.pdf") as pdf:
with pdf.open_metadata() as meta:
meta.clear()
del pdf.docinfo # clears the Info Dictionary
pdf.save("output_clean.pdf")方法5: PDFDealなどのオンラインツールを使う
ソフトウェアのインストールやコードの記述を避けたい場合は、オンラインツールが最も手軽な方法です。 PDFDeal では、PDFをアップロードしてメタデータを削除し、クリーンなファイルをブラウザ上で直接ダウンロードできます。インストール不要なため、一時的な作業や、ソフトウェアをインストールできない環境での利用に便利です。
ただし、機密性の高い文書をサードパーティのサービスにアップロードすることには、それ自体にプライバシー上の考慮が伴います。特に機密性の高いファイルには、ExifToolやAcrobat Proなどのローカルツールを使うのがより安全な選択です。
メタデータが削除されたか確認する方法
PDFのメタデータを削除した後は、ファイルを共有する前に必ず結果を確認してください。クリーンアップが完了したと思い込むことが、情報漏えいの原因になります。
-
ExifTool
-
exiftool cleanfile.pdfを実行して出力を確認します。個人情報ではなく、ファイルサイズやPDFバージョンといった基本的な構造フィールドのみが表示されていれば問題ありません。 - Adobe Acrobat Reader(無料) - ファイル > プロパティ を開き、「説明」タブと「カスタム」タブを確認します。
- オンラインのメタデータビューア - PDFをアップロードして生のメタデータを表示できる無料ツールが複数あります。ソフトウェアをインストールせずに素早く確認したい場合に便利です。
PDFのメタデータを即座に削除 - ソフトウェア不要
PDFをアップロードするだけで、すべての隠しデータを数秒で削除できます。ファイルを共有する前に、作成者名、タイムスタンプ、編集履歴、カスタムプロパティをクリーンアップしましょう。
無料ツールを試す →
確実ではありません。WordへのF変換時に元のPDFメタデータがWordのドキュメントプロパティに引き継がれることが多く、再度PDFに書き出す際に再埋め込みされる場合があります。さらに、Officeライセンスに登録された会社名などのWord固有のフィールドが追加されることもあります。専用のメタデータ削除ツールか、PDFに直接ExifToolを使う方法をお勧めします。
いいえ、解決する問題が異なります。墨消しはページコンテンツから可視テキストや画像を取り除く処理です(例: 契約書の氏名を黒塗りにする)。メタデータ削除は、ファイルの構造に格納された不可視データを取り除く処理です。適切に墨消しされた文書でも、メタデータを通じて作成者名が露出する可能性があるため、多くの場合、両方の処理が必要です。
はい。CreatorフィールドにはオリジナルのアプリケーションF(例: "Microsoft Word")が記録され、ProducerフィールドにはPDFへの変換に使用したツールが記録されます。Authorフィールドにはソースドキュメントの登録ユーザー情報が引き継がれることが多く、タイムスタンプと組み合わせることで、形式変換をまたいでも誰がファイルを作成・編集したかをかなり詳細に把握できてしまいます。
いいえ。標準的なPDFのパスワード保護はページコンテンツを暗号化しますが、メタデータディクショナリはアクセス可能なまま残ります。ExifToolなどのツールは、パスワードなしでパスワード保護されたPDFのメタデータを読み取り・表示できます。プライバシーを目的とする場合は、パスワード保護の前後にメタデータを別途削除する必要があります。
一部の地域ではそのような規定があります。EUのGDPRでは、第三者と文書を共有する際に、作成者名などの文書に埋め込まれた個人データはデータ最小化の原則の対象となります。また、複数の弁護士会では、相手方弁護士や裁判所に文書を送付する前にメタデータを削除することを義務付けた職業倫理規則を設けています。