Usuwanie metadanych z pliku PDF to proces czyszczenia ukrytych informacji zapisanych wewnątrz dokumentu - takich jak imię i nazwisko autora, nazwa oprogramowania użytego do jego tworzenia, historia edycji, a w niektórych przypadkach nawet współrzędne GPS. Większość osób udostępnia pliki PDF nie zdając sobie sprawy, że te dane wędrują razem z plikiem, po cichu ujawniając szczegóły, których nigdy nie zamierzały ujawniać. Niezależnie od tego, czy jesteś prawnikiem przesyłającym umowę, dziennikarzem chroniącym źródło, czy po prostu osobą dbającą o prywatność - wiedza o tym, jak wyczyścić metadane PDF, to praktyczna umiejętność, którą warto mieć.
Spis treści
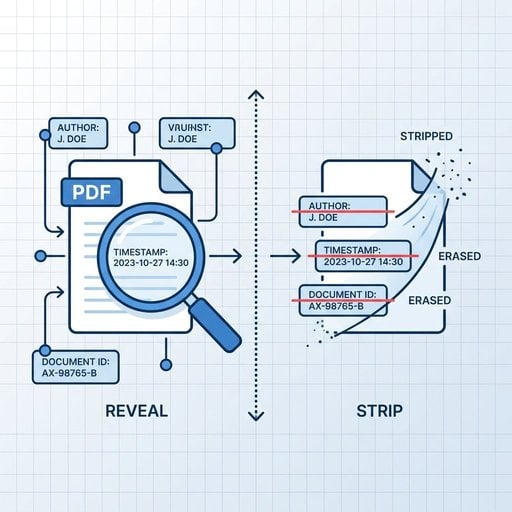
Czym są metadane PDF?
Plik PDF to nie tylko widoczne strony. Wewnątrz struktury pliku specyfikacja PDF firmy Adobe definiuje dwa oddzielne miejsca, w których mogą być przechowywane metadane:
- Document Information Dictionary - starszy magazyn par klucz-wartość osadzony w pliku od wersji PDF 1.0. Zawiera pola takie jak Author, Title, Subject, Keywords, Creator, Producer, CreationDate i ModDate.
- XMP (Extensible Metadata Platform) - nowocześniejszy pakiet oparty na XML, wprowadzony przez Adobe, który może przechowywać znacznie bardziej szczegółowe informacje, w tym właściwości niestandardowe definiowane przez oprogramowanie firm trzecich.
Oba mogą istnieć w tym samym pliku jednocześnie i nie zawsze są ze sobą zgodne. Niektóre narzędzia czyszczą tylko jedno z tych miejsc, pozostawiając drugie nienaruszone - dlatego pobieżne czyszczenie może nadal pozostawiać wrażliwe dane w pliku.
Jakie ukryte dane mogą zostać ujawnione
Oto realistyczny przegląd tego, co możesz znaleźć ukryte w pliku PDF, w zależności od sposobu jego utworzenia:
| Pole metadanych | Co ujawnia | Gdzie się znajduje |
|---|---|---|
| Author | Imię i nazwisko zarejestrowane w oprogramowaniu - często pełne imię i nazwisko osoby lub nazwa użytkownika firmowego | Info Dictionary + XMP |
| Creator / Producer | Aplikacja, która utworzyła plik (np. "Microsoft Word 2019", "Adobe Acrobat Pro DC 2023") | Info Dictionary + XMP |
| Creation Date / Mod Date | Dokładne znaczniki czasu, niekiedy wraz ze strefą czasową, które mogą przeczyć datom podanym w dokumencie | Info Dictionary + XMP |
| Revision History | Ile razy dokument był zapisywany i edytowany | XMP (przestrzeń nazw xmpMM) |
| Document ID | Unikalny identyfikator, który może powiązać ze sobą wiele wersji tego samego dokumentu | XMP |
| Właściwości niestandardowe | Nazwa firmy, dział, status prawny, wewnętrzne tagi - dodawane przez Word, SharePoint lub oprogramowanie prawnicze | Info Dictionary + XMP |
| Osadzone czcionki / zasoby | Nazwy czcionek, które mogą sugerować wewnętrzny branding lub zastrzeżone oprogramowanie | Słownik zasobów PDF |
Realne zagrożenia związane z ukrytymi danymi w PDF
To nie jest problem teoretyczny. Istnieją dobrze udokumentowane przypadki, w których ukryte dane w plikach PDF spowodowały poważne szkody:
- Raport rządu brytyjskiego ws. Iraku (2003) - Rządowy dokument PDF opublikowany w celu uzasadnienia wojny w Iraku zawierał nadal osadzone śledzone zmiany i nazwiska autorów. Dziennikarze wyodrębnili nazwiska urzędników służby cywilnej, którzy sporządzili dokument, co wywołało poważny skandal polityczny.
- Pisma procesowe - Kancelarie prawne przypadkowo składały dokumenty z komentarzami strony przeciwnej, śledzonymi zmianami lub wewnętrznymi notatkami nadal osadzonymi w pliku PDF.
- Dziennikarstwo - Źródło, które ujawnia dokument, może zostać zidentyfikowane, jeśli pole Author lub Document ID w pliku PDF prowadzi do jego danych logowania.
- Przetargi i zamówienia publiczne - Firmy ujawniały swoje wewnętrzne struktury kosztów poprzez niestandardowe pola metadanych dodane przez oprogramowanie księgowe przed złożeniem dokumentów przetargowych.
Jak usunąć metadane z pliku PDF
Istnieje kilka praktycznych sposobów na usunięcie metadanych z PDF, każdy z różnymi kompromisami.
Opcja 1: Adobe Acrobat Pro (Windows / Mac)
To najbardziej kompleksowa opcja desktopowa dla osób, które już mają Acrobat Pro.
- Otwórz plik PDF w Acrobat Pro.
- Przejdź do Narzędzia > Redaguj > Oczyść dokument - ta funkcja usuwa metadane, osadzoną zawartość, skrypty i ukryte warstwy za jednym razem.
- Alternatywnie przejdź do Plik > Właściwości > Opis , aby ręcznie wyczyścić poszczególne pola, ale pamiętaj, że dotyczy to tylko Info Dictionary, a nie XMP.
Opcja 2: ExifTool (bezpłatny, wiersz poleceń)
ExifTool autorstwa Phila Harveya to złoty standard w zakresie manipulacji metadanymi w dziesiątkach formatów plików, w tym PDF. Jest bezpłatny i działa na Windows, Mac oraz Linux.
Aby usunąć wszystkie metadane z pliku PDF:
exiftool -all= yourfile.pdfAby usunąć metadane i zapisać czystą kopię (zachowując oryginał):
exiftool -all= -o cleanfile.pdf yourfile.pdfExifTool usuwa zarówno Info Dictionary, jak i pakiet XMP. Nie usuwa jednak osadzonych czcionek, ukrytych warstw ani komentarzy - do tego potrzebna jest funkcja Oczyść dokument w Acrobat lub dedykowany program do sanityzacji PDF.
Opcja 3: Drukowanie do PDF (szybka metoda)
Otwarcie pliku PDF i wydrukowanie go do nowego PDF za pomocą wbudowanej drukarki PDF systemu operacyjnego (Windows - Drukuj do PDF, macOS - Zapisz jako PDF) usuwa większość metadanych, ponieważ dokument jest w zasadzie ponownie renderowany. Wadą jest to, że może spłaszczyć interaktywne elementy, usunąć zakładki i niekiedy obniżyć jakość. Sprawdza się przy prostych dokumentach tekstowych, ale nie przy złożonych formularzach ani grafice warstwowej.
Opcja 4: Python z pikepdf (dla deweloperów)
Jeśli przetwarzasz pliki PDF programowo, pikepdf to przejrzysta biblioteka Python zbudowana na QPDF, która daje precyzyjną kontrolę nad metadanymi.
import pikepdf
with pikepdf.open("input.pdf") as pdf:
with pdf.open_metadata() as meta:
meta.clear()
del pdf.docinfo # clears the Info Dictionary
pdf.save("output_clean.pdf")Opcja 5: Narzędzie online, np. PDFDeal
Jeśli wolisz nie instalować oprogramowania ani nie pisać kodu, narzędzie online to najszybsze rozwiązanie. PDFDeal pozwala wgrać plik PDF, usunąć jego metadane i pobrać oczyszczony plik bezpośrednio w przeglądarce. Nie wymaga instalacji, co czyni je wygodną opcją dla pojedynczych plików lub gdy pracujesz na komputerze, na którym nie możesz instalować oprogramowania.
Pamiętaj jednak, że przesyłanie poufnych dokumentów do jakiejkolwiek usługi zewnętrznej wiąże się z własnym ryzykiem dla prywatności. W przypadku wysoce poufnych plików bezpieczniejszym wyborem jest lokalne narzędzie, takie jak ExifTool lub Acrobat Pro.
Jak sprawdzić, czy metadane zostały usunięte
Po usunięciu metadanych z pliku PDF zawsze sprawdź wynik przed udostępnieniem pliku. Zakładanie, że czyszczenie zadziałało, to sposób na wycieki danych.
-
ExifTool
- Uruchom
exiftool cleanfile.pdfi sprawdź wynik. Powinieneś zobaczyć tylko podstawowe pola strukturalne (rozmiar pliku, wersja PDF), a nie dane osobowe. - Adobe Acrobat Reader (bezpłatny) - Przejdź do Plik > Właściwości i sprawdź zakładki Opis oraz Niestandardowe.
- Przeglądarki metadanych online - Kilka bezpłatnych narzędzi pozwala wgrać plik PDF i wyświetlić jego surowe metadane. Przydatne do szybkiej weryfikacji bez instalowania oprogramowania.
Usuń metadane z PDF natychmiast - bez instalowania oprogramowania
Wgraj swój plik PDF i usuń wszystkie ukryte dane w kilka sekund. Wyczyść nazwiska autorów, znaczniki czasu, historię edycji i właściwości niestandardowe przed udostępnieniem dokumentu.
Wypróbuj nasze bezpłatne narzędzie →
Nie w sposób niezawodny. Konwersja do Worda często importuje oryginalne metadane PDF do właściwości dokumentu Word, a ponowny eksport do PDF może je ponownie osadzić - niekiedy z dodatkowymi polami specyficznymi dla Worda, takimi jak nazwa firmy z licencji Office. Lepiej użyć dedykowanego narzędzia do usuwania metadanych lub ExifTool bezpośrednio na pliku PDF.
Nie - rozwiązują różne problemy. Redakcja usuwa widoczny tekst lub obrazy z zawartości strony (np. zamazanie nazwiska w umowie). Usuwanie metadanych czyści niewidoczne dane przechowywane w strukturze pliku. Prawidłowo zredagowany dokument może nadal ujawniać nazwisko autora poprzez metadane, dlatego oba kroki są często potrzebne jednocześnie.
Tak. Pole Creator rejestruje oryginalną aplikację (np. "Microsoft Word"), a pole Producer rejestruje, co przekonwertowało plik do PDF. Pole Author często przenosi się z zarejestrowanego użytkownika dokumentu źródłowego. W połączeniu ze znacznikami czasu może to dać dość szczegółowy obraz tego, kto utworzył i modyfikował plik, nawet po konwersjach między formatami.
Nie. Standardowe zabezpieczenie hasłem PDF szyfruje zawartość stron, ale pozostawia słownik metadanych dostępnym. Narzędzia takie jak ExifTool mogą odczytać i wyświetlić metadane pliku PDF chronionego hasłem bez potrzeby jego podawania. Jeśli celem jest prywatność, musisz osobno usunąć metadane przed dodaniem lub po dodaniu zabezpieczenia hasłem.
W niektórych jurysdykcjach tak. Na mocy RODO w UE dane osobowe osadzone w dokumencie (takie jak imię i nazwisko autora) podlegają zasadzie minimalizacji danych przy udostępnianiu osobom trzecim. Kilka izb adwokackich ma również zasady etyki zawodowej zobowiązujące prawników do czyszczenia metadanych z dokumentów przed przesłaniem ich do strony przeciwnej lub sądów.