PDF 元数据清除,是指从 PDF 文件中剥离那些隐藏信息的过程 - 比如作者姓名、创建软件、修订历史,甚至在某些情况下还包含 GPS 坐标。大多数人在分享 PDF 时根本没意识到,这些数据会随着文件一起传出去,悄悄暴露出他们从未打算公开的内容。无论你是发送合同的律师、保护消息来源的记者,还是普通的隐私敏感用户,掌握如何清除 PDF 中的隐藏数据都是一项很实用的技能。
什么是 PDF 元数据?
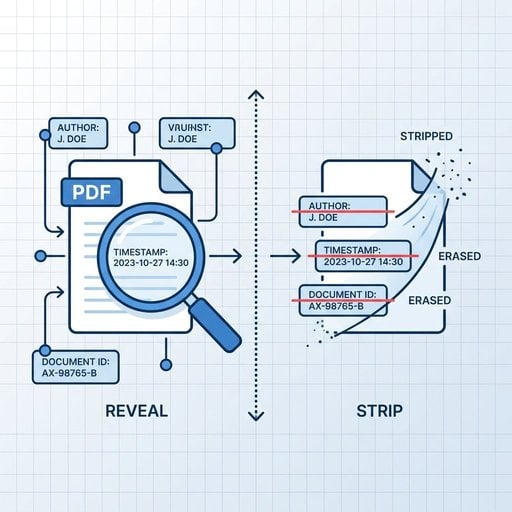
PDF 文件不仅仅是你看到的那几页内容。在文件结构内部,Adobe 的 PDF 规范 定义了两个独立的元数据存储位置:
- 文档信息字典(Document Information Dictionary) - 自 PDF 1.0 起就内嵌于文件中的传统键值存储结构,包含 Author、Title、Subject、Keywords、Creator、Producer、CreationDate、ModDate 等字段。
- XMP(可扩展元数据平台,Extensible Metadata Platform) - Adobe 引入的一种更现代的基于 XML 的数据包格式,可以存储更丰富的信息,包括第三方软件自定义的属性字段。
这两者可以同时存在于同一个文件中,而且它们的内容不一定一致。有些工具只清除其中一个,另一个原封不动 - 这就是为什么浅层清理之后,敏感数据仍然可能残留。
哪些隐藏数据会被暴露
以下是一份实际可能藏在 PDF 中的数据清单,具体内容取决于文件的创建方式:
| 元数据字段 | 可能暴露的内容 | 存储位置 |
|---|---|---|
| Author(作者) | 注册到软件的姓名 - 通常是真实的个人全名或公司账户名 | 信息字典 + XMP |
| Creator / Producer(创建者/生成器) | 生成该文件的应用程序(例如:"Microsoft Word 2019"、"Adobe Acrobat Pro DC 2023") | 信息字典 + XMP |
| 创建日期 / 修改日期 | 精确的时间戳,有时包含时区信息,可能与文档中声称的日期相矛盾 | 信息字典 + XMP |
| 修订历史 | 文档被保存和编辑的次数 | XMP(xmpMM 命名空间) |
| 文档 ID | 可将同一文档的多个版本关联在一起的唯一标识符 | XMP |
| 自定义属性 | 公司名称、部门、法律状态、内部标签 - 由 Word、SharePoint 或法律软件添加 | 信息字典 + XMP |
| 内嵌字体 / 资源 | 字体名称,可能暗示内部品牌或专有软件信息 | PDF 资源字典 |
PDF 隐藏数据的真实风险
这不是假设性的问题。历史上有多起有据可查的案例,PDF 隐藏数据造成了严重后果:
- 英国托尼·布莱尔伊拉克报告事件(2003年) - 英国政府发布的一份用于支持伊拉克战争决策的 PDF 文件,仍然内嵌了修订记录和作者姓名。记者从中提取出了起草该文件的公务员姓名,引发了严重的政治风波。
- 法律文件归档 - 律师事务所曾不慎将含有对方律师评论、修订记录或内部备注的文件提交给法院,这些信息仍内嵌在 PDF 中。
- 新闻报道领域 - 如果泄露文件的内部人士所提供的 PDF 中,Author 字段或文档 ID 与其登录凭据相关联,其身份就可能被追溯。
- 采购与招标 - 有公司在提交招标文件前,未清除会计软件自动添加的自定义元数据字段,导致内部成本结构意外泄露。
如何清除 PDF 元数据
清除 PDF 元数据有几种实用方法,各有不同的取舍。
方法一:Adobe Acrobat Pro(Windows / Mac)
对于已经拥有 Acrobat Pro 的用户来说,这是最彻底的桌面端方案。
- 在 Acrobat Pro 中打开 PDF。
- 前往 工具 > 编辑敏感信息 > 净化文档(Sanitize Document) - 一次性清除元数据、嵌入内容、脚本和隐藏层。
- 也可以前往 文件 > 属性 > 描述 手动清除各个字段,但请注意这种方式只影响信息字典,不会处理 XMP 数据。
方法二:ExifTool(免费,命令行工具)
Phil Harvey 开发的 ExifTool 是处理包括 PDF 在内的数十种文件格式元数据的业界标准工具。完全免费,支持 Windows、Mac 和 Linux。
清除 PDF 所有元数据的命令:
exiftool -all= yourfile.pdf清除元数据并保存为新文件(保留原始文件):
exiftool -all= -o cleanfile.pdf yourfile.pdfExifTool 会同时清除信息字典和 XMP 数据包。但它不会移除内嵌字体、隐藏层或批注 - 这些需要使用 Acrobat 的净化功能或专用 PDF 清理工具来处理。
方法三:打印为 PDF(快速简便)
打开 PDF 并通过操作系统内置的 PDF 打印机(Windows 的"打印到 PDF"或 macOS 的"存储为 PDF")重新输出为新文件,这一过程本质上是重新渲染文档,会剥离大部分元数据。缺点是可能会使交互元素失效、丢失书签,有时还会降低画质。对于简单的文字文档尚可接受,但不适合复杂表单或多层图形文件。
方法四:Python + pikepdf(适合开发者)
如果你需要以编程方式批量处理 PDF, pikepdf 是一个基于 QPDF 构建的简洁 Python 库,可以精确控制元数据的读写操作。
import pikepdf
with pikepdf.open("input.pdf") as pdf:
with pdf.open_metadata() as meta:
meta.clear()
del pdf.docinfo # clears the Info Dictionary
pdf.save("output_clean.pdf")方法五:使用在线工具(如 PDFDeal)
如果你不想安装软件或编写代码,在线工具是最快捷的选择。 PDFDeal 支持直接在浏览器中上传 PDF、清除元数据并下载处理后的文件,无需任何安装,非常适合临时处理单个文件,或在无法安装软件的设备上使用。
需要注意的是,将敏感文件上传至任何第三方服务都存在一定的隐私风险。对于高度机密的文件,建议优先使用 ExifTool 或 Acrobat Pro 等本地工具进行处理。
如何验证元数据已被清除
清除 PDF 元数据之后,在分享文件前务必验证处理结果。盲目假设清理成功,正是信息泄露的根源。
-
ExifTool
- 运行
exiftool cleanfile.pdf并检查输出内容。正常情况下应只显示基本的结构性字段(文件大小、PDF 版本),而不包含任何个人信息。 - Adobe Acrobat Reader(免费版) - 前往 文件 > 属性 ,检查"描述"和"自定义"选项卡中的内容。
- 在线元数据查看工具 - 有多款免费工具支持上传 PDF 并显示其原始元数据,适合在不安装软件的情况下快速进行验证。
上传你的 PDF,几秒内移除所有隐藏数据。在分享文件前,彻底清除作者姓名、时间戳、修订历史和自定义属性。
免费试用 →
不可靠。将 PDF 转换为 Word 时,原始 PDF 的元数据通常会被导入到 Word 文档自身的属性中,再导出为 PDF 时可能重新嵌入 - 有时还会附带额外的 Word 专属字段,例如你 Office 许可证中注册的公司名称。建议直接使用专用的元数据清除工具或 ExifTool 对 PDF 进行处理。
不是,两者解决的是不同的问题。内容编辑(墨涂)是从页面内容中移除可见的文字或图像(比如将合同中的姓名涂黑);元数据清除则是删除存储在文件结构中的不可见数据。一份经过正确墨涂的文档,仍然可能通过元数据暴露作者姓名,因此两个步骤往往需要同时进行。
可以。Creator 字段记录了原始应用程序(例如"Microsoft Word"),Producer 字段记录了将其转换为 PDF 的工具。Author 字段通常会从源文档注册用户信息中继承过来。结合时间戳,即使经过格式转换,这些信息也能拼凑出文件创建者和编辑者的详细画像。
不能。标准的 PDF 密码保护只加密页面内容,元数据字典仍然可以被直接访问。ExifTool 等工具无需密码即可读取并显示受密码保护的 PDF 的元数据。如果目的是保护隐私,需要在添加密码保护之前或之后,单独对元数据进行清除处理。
在某些司法管辖区,确实有此要求。根据欧盟 GDPR 的规定,文档中内嵌的个人数据(例如作者姓名)在与第三方共享时须遵循数据最小化原则。此外,多个律师协会的职业行为准则也要求律师在向对方律师或法院提交文件之前,清除文档中的元数据。