PDF metadata हटाना एक ऐसी प्रक्रिया है जिसमें PDF फाइल के अंदर छुपी हुई जानकारी को हटाया जाता है - जैसे लेखक का नाम, फाइल बनाने में इस्तेमाल किया गया सॉफ्टवेयर, संपादन इतिहास, और कुछ मामलों में GPS निर्देशांक भी। अधिकांश लोग PDF शेयर करते समय यह नहीं जानते कि यह डेटा फाइल के साथ चुपचाप जाता है और ऐसी जानकारी उजागर कर देता है जो वे कभी साझा नहीं करना चाहते थे। चाहे आप कोई अनुबंध भेजने वाले वकील हों, किसी स्रोत की सुरक्षा करने वाले पत्रकार हों, या बस अपनी गोपनीयता की परवाह करने वाले व्यक्ति हों - PDF से hidden data हटाना एक व्यावहारिक कौशल है जो सबके काम आता है।
विषय सूची
PDF Metadata क्या होता है?
एक PDF फाइल केवल दिखने वाले पृष्ठों तक सीमित नहीं होती। फाइल की आंतरिक संरचना में, Adobe की PDF specification दो अलग-अलग स्थान परिभाषित करती है जहां metadata रह सकता है:
- Document Information Dictionary - यह एक पुरानी key-value store है जो PDF 1.0 से फाइल में एम्बेड होती है। इसमें Author, Title, Subject, Keywords, Creator, Producer, CreationDate और ModDate जैसे फील्ड होते हैं।
- XMP (Extensible Metadata Platform) - यह Adobe द्वारा पेश किया गया एक आधुनिक XML-आधारित packet है जो तृतीय-पक्ष सॉफ्टवेयर द्वारा परिभाषित कस्टम प्रॉपर्टी सहित बहुत अधिक विस्तृत जानकारी संग्रहीत कर सकता है।
दोनों एक ही फाइल में एक साथ मौजूद हो सकते हैं, और वे हमेशा एक-दूसरे से मेल नहीं खाते। कुछ टूल केवल एक को साफ करते हैं और दूसरे को वैसे ही छोड़ देते हैं - यही कारण है कि एक सतही सफाई के बाद भी संवेदनशील डेटा पीछे रह सकता है।
कौन सा छुपा डेटा वास्तव में उजागर होता है
फाइल कैसे बनाई गई थी, इस पर निर्भर करते हुए PDF में क्या छुपा हो सकता है, इसका एक व्यावहारिक विवरण यहां दिया गया है:
| Metadata फील्ड | क्या उजागर होता है | कहां रहता है |
|---|---|---|
| Author | सॉफ्टवेयर में पंजीकृत नाम - अक्सर किसी व्यक्ति का पूरा नाम या कंपनी का उपयोगकर्ता नाम | Info Dictionary + XMP |
| Creator / Producer | फाइल बनाने वाला एप्लिकेशन (जैसे "Microsoft Word 2019", "Adobe Acrobat Pro DC 2023") | Info Dictionary + XMP |
| Creation Date / Mod Date | सटीक टाइमस्टैम्प, कभी-कभी timezone सहित, जो दस्तावेज़ में दावा की गई तारीखों से मेल नहीं खा सकते | Info Dictionary + XMP |
| Revision History | दस्तावेज़ को कितनी बार सहेजा और संपादित किया गया | XMP (xmpMM namespace) |
| Document ID | एक अद्वितीय पहचानकर्ता जो एक ही दस्तावेज़ के कई संस्करणों को आपस में जोड़ सकता है | XMP |
| Custom Properties | कंपनी का नाम, विभाग, कानूनी स्थिति, आंतरिक टैग - Word, SharePoint या कानूनी सॉफ्टवेयर द्वारा जोड़े गए | Info Dictionary + XMP |
| Embedded Fonts / Resources | Font के नाम जो आंतरिक ब्रांडिंग या proprietary सॉफ्टवेयर का संकेत दे सकते हैं | PDF resource dictionary |
PDF Hidden Data के वास्तविक जोखिम
यह कोई काल्पनिक समस्या नहीं है। ऐसे कई दर्ज मामले हैं जहां PDF hidden data ने गंभीर नुकसान पहुंचाया:
- Tony Blair Iraq Dossier (2003) - इराक युद्ध को उचित ठहराने के लिए जारी की गई एक UK सरकारी PDF में tracked changes और लेखकों के नाम अभी भी एम्बेड थे। पत्रकारों ने उन सरकारी अधिकारियों के नाम निकाल लिए जिन्होंने दस्तावेज़ तैयार किया था, जिससे एक बड़ा राजनीतिक विवाद खड़ा हो गया।
- कानूनी दाखिले - कानूनी फर्मों ने गलती से ऐसे दस्तावेज़ दाखिल किए हैं जिनमें विरोधी पक्ष की टिप्पणियां, tracked changes या आंतरिक नोट्स अभी भी PDF में एम्बेड थे।
- पत्रकारिता - कोई स्रोत जो कोई दस्तावेज़ लीक करता है, उसकी पहचान हो सकती है यदि PDF का Author फील्ड या Document ID उनके लॉगिन क्रेडेंशियल से जुड़ा हो।
- खरीद और बोली प्रक्रिया - कंपनियों ने टेंडर दस्तावेज़ जमा करने से पहले अपने अकाउंटिंग सॉफ्टवेयर द्वारा जोड़े गए custom metadata फील्ड के जरिए अपनी आंतरिक लागत संरचना उजागर कर दी है।
PDF Metadata कैसे हटाएं
PDF metadata हटाने के कई व्यावहारिक तरीके हैं, जिनमें से हर एक के अपने फायदे और सीमाएं हैं।
विकल्प 1: Adobe Acrobat Pro (Windows / Mac)
जिन लोगों के पास पहले से Acrobat Pro है, उनके लिए यह सबसे संपूर्ण डेस्कटॉप विकल्प है।
- Acrobat Pro में PDF खोलें।
- Tools > Redact > Sanitize Document पर जाएं - यह एक ही बार में metadata, एम्बेड की गई सामग्री, स्क्रिप्ट और छुपी हुई लेयर हटा देता है।
- वैकल्पिक रूप से, File > Properties > Description पर जाकर अलग-अलग फील्ड मैन्युअल रूप से साफ करें, लेकिन ध्यान रखें कि यह केवल Info Dictionary को प्रभावित करता है, XMP को नहीं।
विकल्प 2: ExifTool (मुफ्त, कमांड लाइन)
Phil Harvey का ExifTool PDF सहित दर्जनों फाइल प्रकारों में metadata संपादन के लिए एक मानक टूल है। यह मुफ्त है और Windows, Mac और Linux पर चलता है।
PDF से सभी metadata हटाने के लिए:
exiftool -all= yourfile.pdfMetadata हटाकर एक साफ कॉपी सहेजने के लिए (मूल फाइल को बनाए रखते हुए):
exiftool -all= -o cleanfile.pdf yourfile.pdfExifTool Info Dictionary और XMP packet दोनों को हटा देता है। हालांकि, यह एम्बेड किए गए fonts, छुपी हुई लेयर या टिप्पणियां नहीं हटाता - उनके लिए आपको Acrobat का Sanitize फंक्शन या एक समर्पित PDF sanitizer की जरूरत होगी।
विकल्प 3: PDF में प्रिंट करें (त्वरित और सरल तरीका)
PDF खोलकर अपने ऑपरेटिंग सिस्टम के बिल्ट-इन PDF प्रिंटर (Windows Print to PDF, macOS Save as PDF) से एक नई PDF में प्रिंट करने पर अधिकांश metadata हट जाता है क्योंकि यह दस्तावेज़ को फिर से रेंडर करता है। इसका नुकसान यह है कि इंटरएक्टिव तत्व फ्लैट हो सकते हैं, बुकमार्क खो सकते हैं और कभी-कभी गुणवत्ता कम हो सकती है। सरल टेक्स्ट दस्तावेज़ों के लिए यह ठीक है, लेकिन जटिल फॉर्म या layered ग्राफिक्स के लिए नहीं।
विकल्प 4: Python के साथ pikepdf (डेवलपर्स के लिए)
यदि आप प्रोग्रामेटिक रूप से PDF प्रोसेस कर रहे हैं, तो pikepdf एक साफ Python लाइब्रेरी है जो QPDF पर बनी है और आपको metadata पर सटीक नियंत्रण देती है।
import pikepdf
with pikepdf.open("input.pdf") as pdf:
with pdf.open_metadata() as meta:
meta.clear()
del pdf.docinfo # clears the Info Dictionary
pdf.save("output_clean.pdf")विकल्प 5: PDFDeal जैसे ऑनलाइन टूल का उपयोग करें
यदि आप सॉफ्टवेयर इंस्टॉल नहीं करना चाहते या कोड नहीं लिखना चाहते, तो एक ऑनलाइन टूल सबसे तेज़ रास्ता है। PDFDeal आपको PDF अपलोड करने, उसका metadata हटाने और साफ की गई फाइल सीधे ब्राउज़र में डाउनलोड करने की सुविधा देता है। कोई इंस्टॉलेशन की जरूरत नहीं, जो इसे एकल फाइलों के लिए या ऐसी मशीन पर काम करते समय एक सुविधाजनक विकल्प बनाता है जहां आप सॉफ्टवेयर इंस्टॉल नहीं कर सकते।
ध्यान रखें कि किसी भी तृतीय-पक्ष सेवा पर संवेदनशील दस्तावेज़ अपलोड करने में अपनी गोपनीयता संबंधी विचार होते हैं। अत्यधिक गोपनीय फाइलों के लिए, ExifTool या Acrobat Pro जैसा स्थानीय टूल अधिक सुरक्षित विकल्प है।
Metadata हटने की पुष्टि कैसे करें
PDF metadata हटाने के बाद, फाइल शेयर करने से पहले हमेशा परिणाम की जांच करें। यह मानकर चलना कि सफाई हो गई - इसी से डेटा लीक होता है।
-
ExifTool
-
exiftool cleanfile.pdfचलाएं और आउटपुट जांचें। आपको केवल बुनियादी संरचनात्मक फील्ड (फाइल साइज, PDF संस्करण) दिखने चाहिए, व्यक्तिगत डेटा नहीं। - Adobe Acrobat Reader (मुफ्त) - File > Properties पर जाएं और Description तथा Custom टैब जांचें।
- ऑनलाइन metadata व्यूअर - कई मुफ्त टूल आपको PDF अपलोड करके उसका raw metadata देखने देते हैं। सॉफ्टवेयर इंस्टॉल किए बिना त्वरित जांच के लिए उपयोगी।
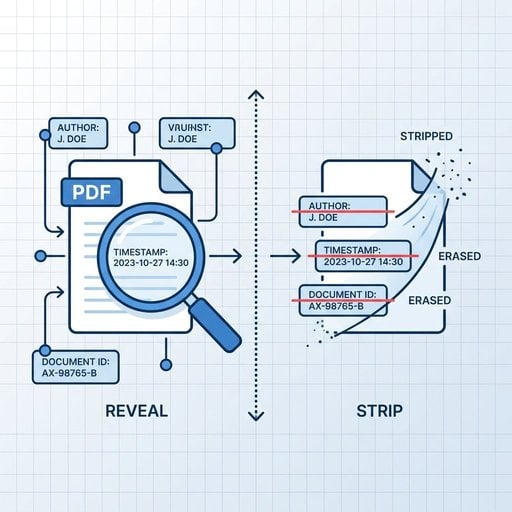
PDF Metadata तुरंत हटाएं - कोई सॉफ्टवेयर नहीं चाहिए
अपनी PDF अपलोड करें और सेकंडों में सभी hidden data हटाएं। फाइल शेयर करने से पहले लेखक का नाम, टाइमस्टैम्प, संपादन इतिहास और custom properties साफ करें।
हमारा मुफ्त टूल आज़माएं →
भरोसेमंद तरीके से नहीं। Word में बदलने पर अक्सर मूल PDF का metadata Word दस्तावेज़ की अपनी प्रॉपर्टी में आ जाता है, और फिर वापस PDF में निर्यात करने पर वह फिर से एम्बेड हो सकता है - कभी-कभी आपके Office लाइसेंस की कंपनी के नाम जैसे अतिरिक्त Word-विशिष्ट फील्ड के साथ। बेहतर है कि PDF पर सीधे ExifTool या किसी समर्पित metadata हटाने वाले टूल का उपयोग करें।
नहीं - ये दोनों अलग-अलग समस्याएं हल करते हैं। Redaction पृष्ठ की दृश्य सामग्री से टेक्स्ट या छवियां हटाता है (जैसे किसी अनुबंध में किसी नाम को काला करना)। Metadata हटाना फाइल की संरचना में संग्रहीत अदृश्य डेटा को साफ करता है। एक सही तरीके से redact किया गया दस्तावेज़ भी metadata के जरिए लेखक का नाम उजागर कर सकता है, इसलिए अक्सर दोनों कदम एक साथ जरूरी होते हैं।
हां। Creator फील्ड मूल एप्लिकेशन (जैसे "Microsoft Word") रिकॉर्ड करता है, जबकि Producer फील्ड यह रिकॉर्ड करता है कि इसे PDF में किसने बदला। Author फील्ड अक्सर स्रोत दस्तावेज़ के पंजीकृत उपयोगकर्ता से आता है। टाइमस्टैम्प के साथ मिलकर, यह फॉर्मेट रूपांतरण के बाद भी फाइल बनाने और संशोधित करने वाले व्यक्ति की काफी विस्तृत तस्वीर बना सकता है।
नहीं। मानक PDF पासवर्ड सुरक्षा पृष्ठ की सामग्री को एन्क्रिप्ट करती है लेकिन metadata dictionary को सुलभ छोड़ देती है। ExifTool जैसे टूल बिना पासवर्ड के भी पासवर्ड-सुरक्षित PDF का metadata पढ़ और दिखा सकते हैं। यदि गोपनीयता लक्ष्य है, तो आपको पासवर्ड सुरक्षा जोड़ने से पहले या बाद में metadata अलग से हटाना होगा।
कुछ क्षेत्राधिकारों में, हां। EU में GDPR के तहत, किसी दस्तावेज़ में एम्बेड किया गया व्यक्तिगत डेटा (जैसे लेखक का नाम) तृतीय पक्षों के साथ साझा करते समय डेटा न्यूनीकरण सिद्धांतों के अधीन है। कई बार एसोसिएशन के पास व्यावसायिक आचरण नियम भी हैं जो वकीलों को विरोधी पक्ष या अदालतों को दस्तावेज़ भेजने से पहले metadata साफ करने की आवश्यकता रखते हैं।